
我们经常在 Between the Data 上讨论不同的定性数据分析方法,例如筛选和理解研究生成的数据的不同方法。我们通常不谈论定性研究中编码的实际、具体方面——尤其是在与团队一起编码时。
Lindsay Giesen 是马里兰州罗克维尔 Westat 的首席研究员。她拥有超过 15 年的政策研究和项目评估经验,她的工作重点是儿童营养和食品安全。在代表美国农业部(USDA) 进行的一项研究中,她开发了一种管理定性数据编码团队的方法,她认为这种方法提高了分析和最终报告的质量。Giesen 与 Stacy Penna 博士一起参加了《数据之间:第 19 集》节目,讨论了她构建、培训和管理定性数据编码员的方法。
在本案例研究中,我们将介绍他们谈话的重点,包括 Giesen 的编码方法、分析过程以及定性数据分析软件 (QDA) NVivo的使用。
定性研究编码指南的研究项目背景和推理
吉森和她的团队受命为美国农业部食品和营养服务部开展一项研究。目标是了解学校、学区和州如何收集联邦资助的儿童营养计划的数据,包括国家学校午餐计划和学校早餐计划。该项目涉及 2018 年春季在四个州的实地考察。该团队对学校食堂工作人员、学区官员和州教育官员进行了 154 次采访。
该团队有六周的周转时间来完成所有访谈数据的定性编码。Giesen 和她的团队明白,为了在最后期限前完成任务,必须采取结构化的方式来培训和监督他们的编码员。她在这个项目中学到了三个重要的教训:
- 为你的团队建立一个有多层支持的管理结构
- 采取循序渐进的方式进行培训,按顺序培养技能,而不是试图一次性教会团队一切
- 创建非常详细的参考资料来指导您的团队工作
定性数据编码团队的多层管理结构:持续沟通,更好协作
首先,吉森将工作分配给了每位程序员。她的团队在四个不同的州进行了采访,因此每位程序员都被分配到一个州进行工作。吉森强调,这些程序员并不是对笔录一无所知的。
“程序员是初级员工,他们曾是我们进行现场访问时的支持人员,”吉森解释道。“所以他们了解数据,了解访谈和受访者。”
接下来,每位程序员都会被分配一名高级审核员。审核员将担任每次现场访问的负责人。
高级评审员向首席分析师吉森 (Giesen) 汇报。还聘请了一位外部方法学家,对团队的流程提供客观的反馈。
“我们每个人都有自己的支持人员,这非常有帮助,”吉森解释道。“有人可以检查你的工作,也有人可以与你交流想法和问题,这为我们创造了一个非常好的结构。”
这种结构是协作的,层次结构中不同层级之间不断沟通。这种问题和反馈的流动使得问题可以在流程的早期被标记,从而可以改进编码方案和其他流程。
编码方法:分阶段训练以获得更高质量的编码
接下来,吉森和方法学家为编码员和审阅者组织了一次培训。
吉森说:“我以前曾在编码团队工作过……在那里,我会得到指示和代码列表,然后就可以自己处理事情了。”
吉森不希望这种情况发生在她的程序员身上,她也不想让他们被信息淹没。她采取了多步骤的培训方法。
步骤 1:定性数据编码现场培训
首先,她的团队参加了为期一天的面对面培训课程,内容涵盖了基本编码技能以及学习如何使用 NVivo 定性分析软件。当天的第一部分是使用纸张和荧光笔进行手动编码——逐行编码。
“定性数据中有很多噪音,”吉森说,“你需要从概念上教会程序员如何筛选噪音,找到你想要的东西。”

她让编码员使用练习记录,圈出记录的各个部分,并注意她创建的代码数据库中的哪些代码可能适用。这发展到使用 Microsoft Word 文档突出显示要编码的特定文本部分,并决定何时应用多个代码。使用一组预定义的代码,然后将它们分配给数据,这称为演绎编码。另一种方法是归纳编码,即从定性数据中得出代码。
“我发现 [NVivo] 非常有价值,而且我认为团队很快就掌握了它……我们希望确保每个人都对如何使用它有共同的理解。”
第 2 步:练习和虚拟复习编码转录脚本
经过一天的培训课程后,吉森让团队开始编写最简单、最简短的记录——学校层面的采访。这样一来,编码员们就可以使用她为该项目创建的约 200 个代码中的一小部分。
吉森举行了一场较短的远程培训会议,她在会议中分享了自己的屏幕,并向团队介绍了她认为哪些代码适用于数据。这些培训会议还包括一个简短的练习课和提问时间。程序员和审阅者将在会议结束后选择一份指定的记录,与审阅者进行讨论。
步骤 3:问答环节和时间表回顾
几天后,团队再次召开线上签到会议。每个人都带来了各自分配的记录中的问题。
“它指出了程序员不确定应该将哪种代码应用于特定文本的地方。如果需要,我们会在通话期间收集反馈并改进编码方案,”吉森解释道。
它还让她的团队了解了每个转录脚本需要多长时间来对数据进行编码,以便可以相应地调整截止日期和时间表。

训练、实践、编码
随着团队从学校级别的访谈转向在区和州级别进行的访谈,这种训练-实践-编码过程在为期六周的编码期间不断重复。
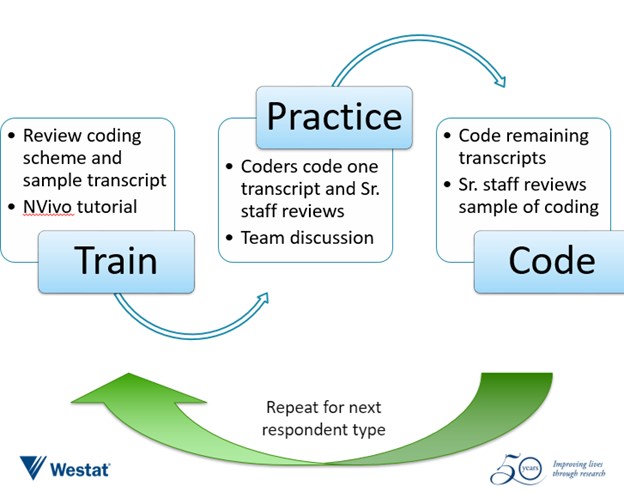
创建详细的参考资料,展示定性数据编码的步骤
定性研究中编码的挑战之一是编码团队之间的一致性。即使是经验丰富的编码员,如果没有充足的参考资料,也很难准确地分配代码,而这些不准确性可能会导致在通过主题分析(识别模式和主题)深入分析和挖掘数据时出现问题。
Giesen 于 2020 年在 Sage International Journal of Qualitative Methods 上发表的文章“构建基于团队的定性数据编码方法”介绍了她为帮助确保主题分析编码的一致性而创建的参考资料。这些资料包括一个 Microsoft Excel 代码本,编码员可以根据他们正在编码的转录脚本类型进行筛选(例如,仅显示学校级访谈的代码)。
此外,还有一份空白的面试问题副本,其中列出了分配给每个问题的最适用代码,以及一份已应用代码的样本记录。在为期六周的编码期间,根据团队反馈对代码簿进行了编辑。

吉森坦言,由于时间紧迫,她最初对将所有这些不同的步骤纳入团队编码流程感到焦虑。然而,最终她制作出了更强大的最终产品。
“通过团队会议,我们给予人们无限的机会提出问题,并不断修改编码方案以更好地适应数据……这使得整个过程非常顺利,”吉森说。“最重要的是,它使我们的分析和报告过程变得更好,因为编码质量很高。”
详细了解吉森的定性编码方法
有兴趣了解有关在编写定性研究代码时管理团队的更多详细信息吗?您可以在Sage International Journal of Qualitative Methods上在线阅读 Lindsay Giesen 于 2020 年合作撰写的论文。
您还可以通过在此处收听完整的播客节目来了解有关这项研究的更多信息。